每日论文速递 |
您所在的位置:网站首页 › 幻觉 知乎用户 › 每日论文速递 |
每日论文速递
|
深度学习自然语言处理 分享整理:pp
https://arxiv.org/abs/2403.02889 Q1: 这篇论文试图解决什么问题?A:这篇论文试图解决大型语言模型(LLMs)在生成文本时出现的“幻觉”问题。所谓的幻觉,指的是LLMs在回答问题时,虽然生成的答案听起来很真实,但实际上与事实不符,没有事实依据。这种现象在LLMs的广泛应用中是一个关键问题,因为它可能导致误导和信任问题。论文提出了一种名为InterrogateLLM的新方法,用于检测LLMs生成的答案中的幻觉,并在多个数据集和LLMs上进行了广泛的评估,以证明该方法的有效性。 Q2: 有哪些相关研究?A:相关研究主要集中在自然语言生成任务中的幻觉现象,包括翻译、摘要、对话生成和问答系统。以下是一些具体的相关工作: 翻译和摘要中的幻觉:Kryscinski等人(2020)和Maynez等人(2020)探讨了在翻译和摘要任务中幻觉的检测。 对话生成中的幻觉:Shuster等人(2021)研究了对话生成中的幻觉问题。 问答系统中的幻觉:Lin等人(2022)在问答系统中测量模型模仿人类错误的方式。 幻觉检测数据集:Liu等人(2022)提出了一个用于自由形式文本生成的幻觉检测基准,该数据集包含文本段落和扰动,目标是确定整个段落是否表现出幻觉。 自我检查GPT:Manakul等人(2023b)引入了SelfCheckGPT,它利用LLMs生成的多个随机样本来评估响应的一致性。 多层感知器分类器:Azaria和Mitchell(2023)提出了一种方法,使用语言模型的隐藏表示来预测句子的真实性。 自我评估技术:Kadavath等人(2022)提出了一种自我评估技术,训练模型预测它们对任何给定自由形式问题的答案的了解程度。 这些研究为理解幻觉现象、开发检测方法以及提高LLMs的可靠性提供了基础。论文中提到的InterrogateLLM方法在这些研究的基础上,提出了一种新的检测幻觉的方法,并通过实验验证了其有效性。 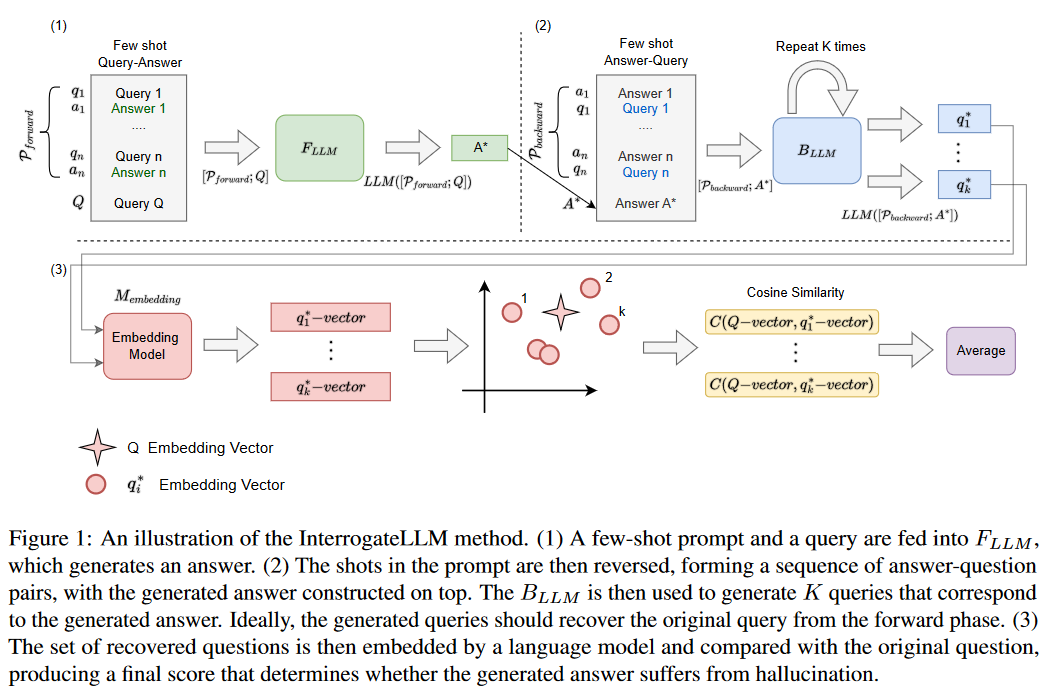 Q3: 论文如何解决这个问题?
Q3: 论文如何解决这个问题?
A:论文提出了一种名为InterrogateLLM的方法来解决大型语言模型(LLMs)中的幻觉问题。这个方法的核心思想是通过重复的查询重构过程来检测模型生成答案中的不一致性,从而识别潜在的幻觉。以下是InterrogateLLM方法的主要步骤: 正向查询:首先,将一个由几个查询-答案对组成的提示(few-shot prompt)和一个特定的查询(Q)输入到前向语言模型(FLLM),以生成一个答案(A*)。 反向重构:然后,通过创建一个新的提示(Pbackward),该提示是将原始提示(Pforward)中的查询-答案对顺序颠倒,形成答案-查询对。接着,将生成的答案(A*)添加到这个反向提示的末尾,并将其传递给一个或多个后向语言模型(BLLM),尝试重构原始查询(Q)。 文本嵌入:使用语言模型将原始查询(Q)和重构的查询(Q*)转换为嵌入向量。 验证:通过计算原始查询向量和重构查询向量之间的余弦相似度,来评估它们之间的一致性。如果相似度低于预设的阈值τ,那么认为生成的答案(A*)可能包含幻觉。 
变量温度:为了提高检测的准确性,论文还探索了在反向过程中使用不同的温度值对结果的影响。温度参数影响模型在生成答案时选择下一个标记的概率分布,通过调整温度,可以增加重构查询的多样性。 实验评估:论文通过在多个数据集和LLMs上进行广泛的实验评估,来验证InterrogateLLM方法的有效性。实验结果表明,该方法能够有效地检测出幻觉,并在不同的数据集和模型上取得了较高的准确率。 通过这种方法,InterrogateLLM能够在不依赖外部知识的情况下,系统地评估和检测LLMs生成文本中的幻觉,从而提高了模型输出的可靠性。 Q4: 论文做了哪些实验?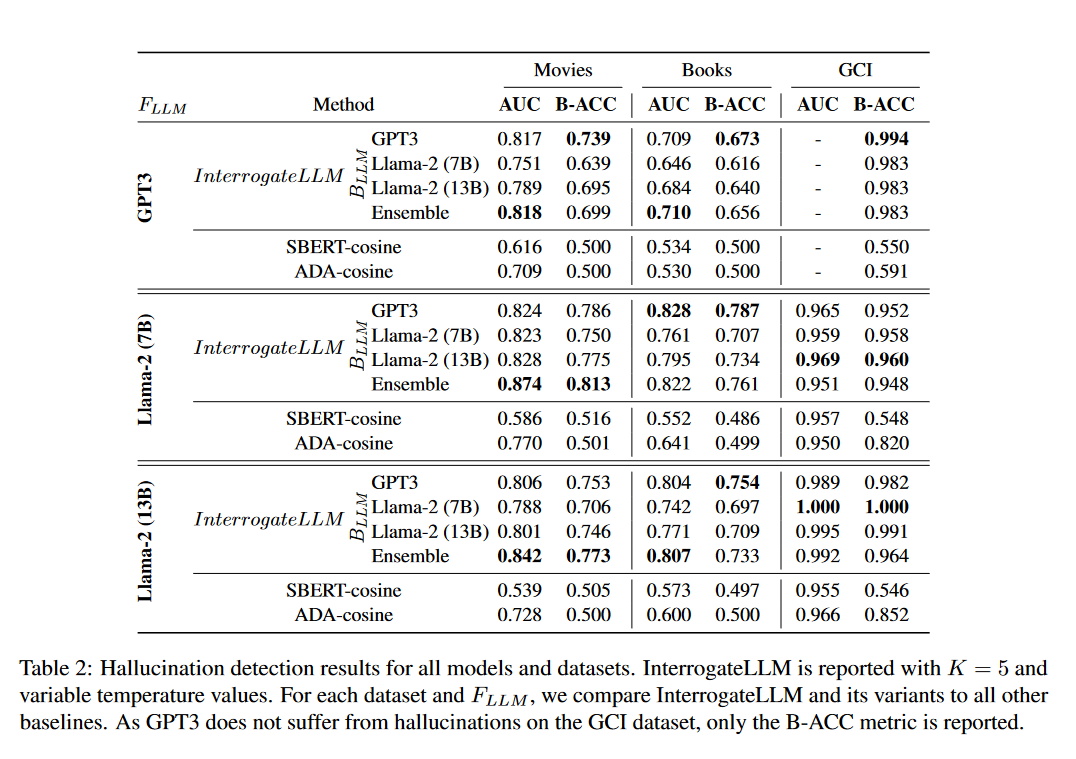
A:论文中进行了一系列实验来评估InterrogateLLM方法在检测大型语言模型(LLMs)生成文本中的幻觉方面的有效性。以下是实验的主要内容: 数据集和任务:选择了三个公共数据集(Movies Dataset、Books Dataset和Global Country Information (GCI) Dataset),并为每个数据集设计了文本生成任务。这些任务涉及预测电影演员阵容、书籍作者和出版年份以及国家首都等信息。 实验设置:实验中使用了不同的LLMs,包括GPT-3和Llama-2(7B和13B版本)。对于每个数据集,研究者们构建了相应的查询-答案对,并使用这些对来训练和测试InterrogateLLM方法。 基线比较:将InterrogateLLM与几种基线方法进行比较,包括SBERT-cosine和ADA-cosine,这些基线方法使用预训练的SBERT模型和OpenAI的ada002模型来计算查询和生成答案之间的余弦相似度。 幻觉率评估:评估了GPT-3和Llama-2在不同数据集上生成答案的幻觉率。这有助于了解不同模型在特定任务上的可靠性。 幻觉检测结果:使用接收者操作特征曲线(ROC)下的面积(AUC)和平衡准确率(B-ACC)作为评估指标,比较了InterrogateLLM及其变体与其他基线方法的性能。 消融和超参数分析:进行了消融研究,以了解在InterrogateLLM中执行多次反向过程(K值)、使用可变温度值(Ti)以及平均函数在余弦相似度计算中的重要性。 温度值的影响:研究了在反向过程中使用不同温度值对检测准确性的影响。通过调整温度,可以增加重构查询的多样性,从而可能提高检测幻觉的能力。 结果分析:分析了实验结果,展示了InterrogateLLM在不同数据集和模型上的性能,并讨论了其在检测幻觉方面的有效性。 这些实验结果表明,InterrogateLLM方法能够有效地检测LLMs生成文本中的幻觉,并且在多个数据集和模型上取得了较高的准确率。此外,实验还揭示了不同模型在幻觉检测任务上的表现差异,为未来改进LLMs的可靠性提供了有价值的见解。 Q5: 有什么可以进一步探索的点?A:尽管InterrogateLLM方法在检测幻觉方面取得了一定的成果,但仍有一些领域可以进一步探索和改进: 多模态数据集:在包含图像、视频或其他非文本信息的数据集上测试InterrogateLLM,以探索其在多模态环境中的适用性和有效性。 不同领域的适应性:在更多特定领域(如医疗、法律、历史等)的数据集上评估InterrogateLLM,以了解其在特定知识领域的性能。 实时检测:将InterrogateLLM集成到实时应用中,例如聊天机器人或虚拟助手,以实时检测和减少幻觉的发生。 改进模型架构:研究不同的模型架构对幻觉检测性能的影响,例如使用Transformer模型的不同变体或结合多种模型的优势。 集成外部知识库:探索将外部知识库(如Wikidata、Freebase等)集成到InterrogateLLM中,以提高检测的准确性和鲁棒性。 用户交互式验证:开发用户交互式的方法,允许用户参与验证过程,以进一步提高幻觉检测的准确性。 幻觉原因分析:深入研究导致幻觉的根本原因,例如模型训练数据的偏差、模型架构的局限性或特定类型的查询。 幻觉缓解策略:开发和测试不同的幻觉缓解策略,例如通过调整训练过程、引入额外的监督信号或使用对抗性训练来减少幻觉的发生。 跨语言和跨文化研究:在不同语言和文化背景下评估InterrogateLLM,以了解其在全球化环境中的适用性。 长期影响评估:研究长期使用InterrogateLLM对模型性能的影响,包括幻觉检测的长期效果和模型对幻觉的适应性。 通过这些进一步的探索,研究者们可以更好地理解幻觉现象,提高LLMs在各种应用场景中的可靠性和用户信任。 Q6: 总结一下论文的主要内容?A:这篇论文介绍了一种名为InterrogateLLM的新型方法,旨在检测大型语言模型(LLMs)在生成文本时可能出现的幻觉问题。幻觉是指模型生成的答案听起来合理,但实际上与事实不符。为了解决这一问题,论文提出了以下主要内容: 问题背景:论文首先讨论了LLMs在日常生活中的广泛应用以及幻觉现象对这些模型可信度的影响。 方法介绍:提出了InterrogateLLM方法,该方法通过重复重构查询过程来检测生成答案中的幻觉。具体来说,它通过比较原始查询和基于生成答案重构的查询之间的一致性来识别幻觉。 实验设计:在多个数据集(包括Movies、Books和GCI数据集)上进行了广泛的实验,以评估InterrogateLLM在不同领域和模型(如GPT-3和Llama-2)上的性能。 结果分析:实验结果表明,InterrogateLLM能够有效地检测幻觉,并且在多个数据集和模型上取得了较高的准确率。特别是,它在Llama-2模型上观察到了高达62%的幻觉率,并在特定实验中达到了87%的平衡准确率(BACC)。 消融研究:进行了消融研究,以了解多次反向过程、可变温度值和平均函数在检测幻觉中的作用。 局限性:论文也讨论了InterrogateLLM方法的一些局限性,例如在处理多对一映射的源和目标域时的挑战,以及在检测半真答案中的幻觉时的困难。 未来工作:最后,论文提出了未来可能的研究方向,包括将InterrogateLLM扩展到检索增强生成设置,以及在更广泛的任务和领域中测试其性能。 总的来说,这篇论文为提高LLMs在实际应用中的可靠性提供了一种新的视角,并为未来的研究和开发工作奠定了基础。 以上内容均由KimiChat生成,深入了解论文内容仍需精读论文 备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群
id:DLNLPer,记得备注呦 |
 摘要:尽管大语言模型(LLMs)取得了许多进步,并以前所未有的速度迅速发展,但由于种种原因,它们对我们日常生活方方面面的影响和整合仍然有限。阻碍其广泛应用的一个关键因素是幻觉的出现,在幻觉中,大型语言模型编造出听起来逼真的答案,但却与事实真相相去甚远。在本文中,我们提出了一种在大型语言模型中检测幻觉的新方法InterrogateLLM,它解决了在各种真实世界场景中采用这些模型的关键问题。通过对包括 Llama-2 在内的多个数据集和 LLM 的广泛评估,我们研究了近期各种 LLM 的幻觉水平,并证明了我们的方法在自动检测幻觉方面的有效性。值得注意的是,在一个特定实验中,我们观察到 Llama-2 的幻觉率高达 62%,我们的方法达到了 87% 的平衡准确率 (B-ACC),而这一切都无需依赖外部知识。
摘要:尽管大语言模型(LLMs)取得了许多进步,并以前所未有的速度迅速发展,但由于种种原因,它们对我们日常生活方方面面的影响和整合仍然有限。阻碍其广泛应用的一个关键因素是幻觉的出现,在幻觉中,大型语言模型编造出听起来逼真的答案,但却与事实真相相去甚远。在本文中,我们提出了一种在大型语言模型中检测幻觉的新方法InterrogateLLM,它解决了在各种真实世界场景中采用这些模型的关键问题。通过对包括 Llama-2 在内的多个数据集和 LLM 的广泛评估,我们研究了近期各种 LLM 的幻觉水平,并证明了我们的方法在自动检测幻觉方面的有效性。值得注意的是,在一个特定实验中,我们观察到 Llama-2 的幻觉率高达 62%,我们的方法达到了 87% 的平衡准确率 (B-ACC),而这一切都无需依赖外部知识。
【本文地址】
今日新闻 |
推荐新闻 |